Introduction: The Inefficiency of “Asking Multiple AIs” Is a Failure of Design
A growing number of business professionals now use ChatGPT, Claude, and Gemini selectively in their work — because each of them responds with different characteristics.
The problem is that this “selective use” has degenerated into a manual back-and-forth. Copy, paste, read across, switch to another window. This is not intellectual work; it is the absence of a process.
1. Design Structure Matters More Than Implementation Means
When you set out to leverage multi-LLM, you have multiple implementation choices.
Direct API calls, multi-agent infrastructure built on LangGraph, parallel queries with diff extraction on a local Dify, or operations through each service’s interface. As I touched on in a previous article, I have experience with all of these configurations and understand their respective design challenges.
But what I want to discuss in this article is not the selection of an implementation means. What is far more important in practice is the question that remains common across whichever means you choose: “By what structure should the outputs of multiple AIs be integrated and used in judgment?”
“Technically possible” and “the optimal design” are different questions. The essence is not in the cleverness of the means, but in the design of the judgment structure.
2. Implementation: A Three-Layer Structure of Refiner → Broadcast → Integrator
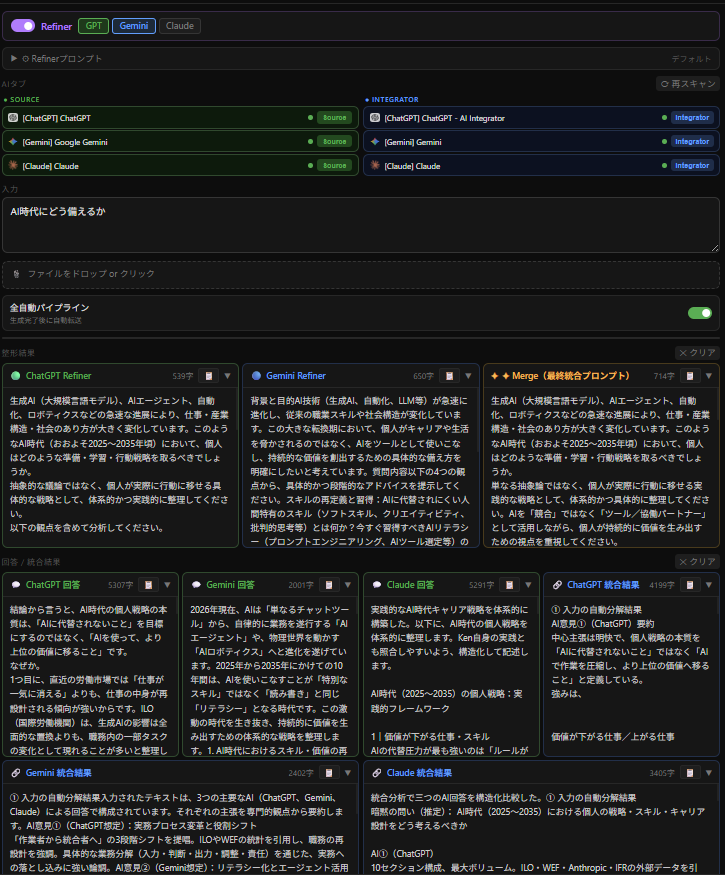
The AI Broadcaster I built operates with the following three-layer structure.
You start by entering, roughly, what you want to ask.

Layer One: Refiner. Reshapes the input query into “the form each AI is most able to process.” It generates a prompt tailored to each selected AI (when multiple are selected, it produces them individually and then integrates them into a final prompt for output).
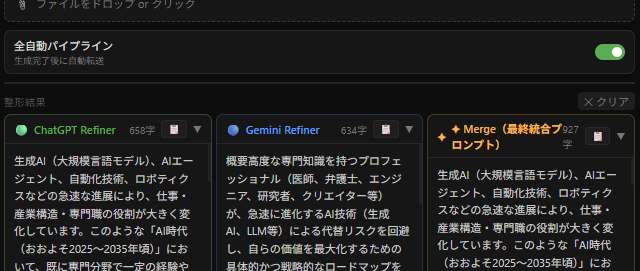
Layer Two: Broadcast. Based on the reshaped prompts, it submits the same question to each selected AI and retrieves their answers.
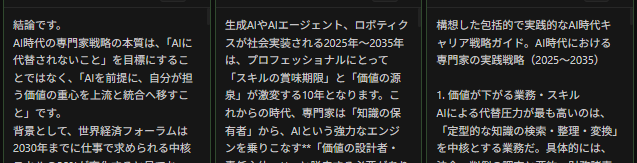
Layer Three: Integrator. Integrates the responses from each AI. The design is to surface points of agreement and divergence across the responses and then generate a final integrated view. The AI in charge of integration is also selectable. For demonstration purposes here, three AIs were each made to perform integration.
By placing the responses side by side and identifying where they agree and where they diverge, you can reinforce perspectives that no single AI would have surfaced alone — and each integrator presents what it considers the best final answer.

Ultimately, you end up with multiple integrated results in hand, and it is simply a matter of examining which to adopt, or where the models agree and where they diverge, and making a judgment accordingly.
3. The Design Question That Took the Most Time
What consumed the most time was not technical implementation but design philosophy: “How much should the system decide, and where should human judgment take over?”
In the initial design, I tried to unify the processing approach across Refiners. However, through experimentation, I found that preserving the individuality of each AI’s Refiner output improved both the diversity and quality of the final answers. A structure that shared only the objective of “optimizing the prompt” while leaving the approach to each AI’s judgment proved effective.
This is structurally identical to organizational decision-making design. If all members are forced into the same thinking framework, diversity is lost and the quality of collective intelligence declines. The same phenomenon occurs in AI consensus design.
4. Governance Implications of Multi-LLM Consensus
Dependency on a single model carries the same risk structure as designing a single point of failure. Diversity of judgment, cross-verification, and transparency of the integration process — these are fundamental requirements in reliability engineering, and the same holds true in the context of AI governance.
To implement the “appropriate understanding and management of AI outputs” required by ISO/IEC 42001 and the NIST AI RMF at the implementation level, a structure is needed that can trace which model made which judgment and on what basis. Multi-LLM consensus design can be one approach that naturally guarantees this structure.
Furthermore, consensus-based approaches can be expected to reduce hallucination risk and mitigate bias. The quality of AI decision-making is not determined solely by the performance of individual models — it changes through the design of the consensus process. This is a systems design problem, and simultaneously a governance problem.
This article represents the personal views of the author based on information available as of March 2026, and does not represent the views of any affiliated or related organization.